A case study of reagent and re-frame using the workshub frontend
Alex Bakic
27 Jan 2020
•
27 min read

In this guide we're going to see how reagent and re-frame find their place in the workshub frontend. It's an important feature of good technologies for them to fit well within your project's domain, and not to spread too many of their own opinions (unless they're quite helpful). With the amount of thought that has gone into the re-frame philosophy, it's structure and standards, it is very rarely the case that it's idioms need to be overwritten, and the results are clean , concise and testable code. This guide doesn't assume familiarity with reagent or re-frame as I'll go over each aspect of the two of them step by step, so by the end we can see how it works, but more importantly see how it holds together a large project, one which the workshub client certainly is.
Understanding Reagent
Reagent is a library aimed at making react as intuitive with clojure as possible. React essentially gives you a way of modelling views and re-rendering state. Reagent builds upon these concepts by fulfilling them the clojure way, by using hiccup for the views and atoms for the state. It is a joy to work with, leaving you with frontend code that is sharp and simple. The most fundamental building block of any react application is an element , which is literally just the html that constitutes a section of the overall frontend. Components are the functions which wrap this snippet of view code, providing it with any data it may need or to transform the html in a certain way. Elements compose html , and components compose elements. The overall view is the composition of components. What feeds the composition of components at startup could be any sort of api , data store , localstorage etc.
In react the term we use for "data passed to components" is called the props , or properties , of a component. In JavaScript land, components take an object (ahh!) and have to pull out from that object what it needs. Reagent has no such convention, and we can make it so each component has only the data it needs. And nothing more. It shouldn't have to know about states that it can do without, which can be used within other isolated components. You should compose components into larger parts of the frontend as it just makes debugging, re-rendering and refactoring a whole lot easier if you keep to this philosophy.
While components come in various shapes and sizes, they can be categorised , and we categorise them by complexity. The simplest , and so the ones with the least amount of working state , are called form-1 components. They are simple because they are pure, and will never render a different view if you don't change their argument(s). One instance where we can see the workshub frontend using them is in the cards describing job posts, with an example just below:
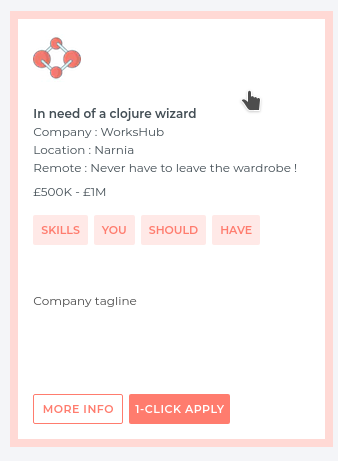
Now I have tweaked it slightly from the ones you would see on site... But this is because I want us to get familiar with reagent syntax and best practice, staying away from any intricacies or business logic while we try to replicate it ourselves for the moment.
The very first thing we should define is the company logo, right at the top of the card:
(defn company-logo
"takes a company logo , or company name in case it cannot be displayed, for the jobs post card."
[logo company-name]
;; reagent uses hiccup syntax for modelling , so the .logo is a hiccup shortcut for defining classes.
[:div.logo
[:img {:src logo
:alt (str company-name " logo")}]])
Looking at this component, we've not referenced reagent at all. We could have defined this component without any knowledge of reagent, so how does it come together? Well, if we wanted to see just this component on screen, what we can do is call reagent.core/render which takes two arguments, one being our component, which we call the render function and a dom node, which we can call the render object. Components as simple as the one above are nothing more than their render function, they take data and return hiccup for translation to html.
;; so to render the company logo onto a div with id "app":
(reagent.core/render [company-logo *the-logo* *the-name*] (.getElementById js/document "app"))
Notice how we don't call the render function with round brackets, but square brackets , like any other hiccup element. There is a difference between square and round brackets, as square brackets indicate to reagent we are supplying a component, and so during the render process it will turn it , and it's children into a react component; whereas if we were to call the function and supply the big hiccup block directly, it is treated as one big data structure and the thorough transformation to react isn't performed, only once on the hiccup block itself. So when data changes in one section of the hiccup block, the entire thing would have to be re-rendered. A much more in-depth explanation on this topic can be found here.
When reagent is getting ready to render our component, it will turn it into a react component, using the native js class React.Component. Reagent makes it so our component extends this class and the core method of the react class is the render method. Simple components are reduced to nothing more than this render function, and so they become it's implementation. More complex components will use other methods of the component class, but the render method will always and must be present. The render function isn't so much the conversion process itself, from hiccup to html , but the function that reagent will call to find what to render.
Important note: calling render on anything outside of the big "super component" is considered bad practice, react didn't give us a Virtual DOM for no reason! But more on that in a moment.
Back to designing our card, the next thing we have to define is the job title and company information : company name , location , job position , perks and salary. Now that's quite a lot! We need to be careful with defining the perks , as some jobs may not have any at all, some may have one or a lot. The current available perks that can be associated with a job are :
remote work
role-type would = "Part time"
sponsorship offering
Whilst a job may not have any perks, the value for role-type would then be "Full time", so we're rendering something. We'll separate this logic from the rest of the information into a different component and call it company-perks:
;; this would be the wrapper component, displaying all company information
(defn job-card-info
[title company-name display-location remote role-type sponsorship-offered]
;; since the data for showing perks is a part of info, it is perfectly fine to
;; accept it with other job card information, as the implementation is decomplected.
[:div.basic-info
[:div.job-title title]
[:div.company-name company-name]
[:div.location display-location]
;; we use the name of our component as the first argument, whenever we want to
;; reference a component as it's underlying elements, it should be done with square brackets,
;; instead of a function which would be called with round brackets.
[company-perks remote role-type sponsorship-offered]
[:div.salary display-salary]])
Now for defining the company-perks component itself.
(defn company-perks
"takes all the potential perks a job can be registered to have.
The base case would be remote and sponsorship are false ,
but role-type would be a value , set to full-time. "
[remote role-type sponsorship-offered]
;; for each truthy value, evaluate the expression associated.
;; [icon ...] is a helper component , and you can find it in
;; client/common/src/wh/components/icons.cljc
(cond-> [:div.card__perks]
remote (conj [icon "job-remote" :class "job__icon--small"] "Remote")
(not= role-type "Full time") (conj [icon "profile" :class "job__icon--small"] role-type)
sponsorship-offered (conj [icon "job-sponsorship" :class "job__icon--small"] "Sponsorship")))
cond-> goes through and adds to our :div whatever benefits this particular job may have. Whilst I've defined the company-perks component after job-card-info in an actual program you should specify it before, otherwise reagent won't be able to find it.
So far we've done the logo and the description for a given company, and now we need to define the skills that they require (the tags). Due to the nature of clojure, reagent and for, writing a view with a lot of repeating elements is very intuitive , as it is just data:
[:ul
(for [item ["a" "few" "tags"]]
[:li item])]
;; => [:ul ([:li "a"] [:li "few"] [:li "tags"])]
This isn't perfect, and reagent isn't too happy we've given it another hiccup block... We know that react wants fine grained control over every aspect of the frontend, to make re-rendering efficient and to enforce decomposition. When we make list elements this way, we are creating hiccup that will be rendered as one big block, when ideally react would've wanted to turn each element into react components, making them unique and therefore trackable. We even get a warning from reagent : every element in a seq should have unique :key for the reason I described. We'll need to supply a unique key for each item, in order for react to distinguish them , which we can do by incorporating the :key into it's attributes directly or it's metadata:
;; adding the key to it's attributes directly
[ul
(for [item ["a" "few" "tags"]]
[:li {:key item} item])]
;; or adding the key to it's metadata
[ul
(for [item ["a" "few" "tags"]]
^{:key item} [:li item])]
It's preferable to use the metadata option, as it doesn't clutter the view , but you can avoid this whole mess by just separating each item with into and going about it using map...
(into [:ul.wrapper]
(map (fn [item] [:li item]) items))
;; => [:ul.wrapper [:li "a"] [:li "few"] [:li "tags"]]
Now let's use what we've learnt and define the company-tags function:
(defn job-card-tags
[tags]
(into [:ul.tags.tags__job]
(map (fn [tag]
[:li {:on-click
;; reagent doesn't handle events itself, so imagine any old function
;; that takes us to a page where we can see other clojure jobs
;; if we clicked on the clojure tag
;; this is where re-frame will come in ...
#(see-jobs-of-this-tag tag)} tag])
tags)))
Looking back on the design of our card, I think needs a bit of spicing up, maybe it's too simple. I'll take this moment to showcase form-2 components, as adding a bit of state which changes over time can be really eye-catching. The plan is to show the number of likes a job post gets. This is determined by how many people click the "Heart" button to which does the job of incrementing the like count.
We should hope to have it look like this:
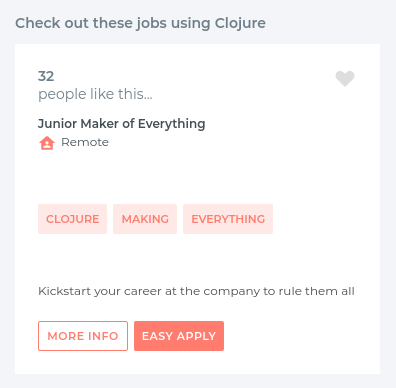
And when we highlight said card:
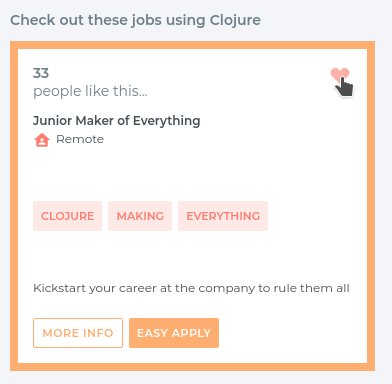
All the actual code is all ready and waiting for us to string it together, we just need to set up the r/atom:
(defn like-job-post
"when we click the heart icon it should increment the like count atom, and as it dereferences,
we see how popular the job is getting. But as it is , this is all local state . And the only
people liking it is us..."
[]
(let [likes (r/atom 0)]
(fn []
[:div.likes
[:h2 @likes (if (= 1 @likes) [:h4 " person likes this..."] [:h4 " people like this..."])]
[:span
[icon "like"
:id (str "job-card__like-button_job-" 3)
:class "job__icon like job__icon__private job__icon--pointer"
:on-click #(swap! likes inc)]]])))
When reagent gets to work on creating a React.Component class out of this, reagent will check to see , after the component is invoked with square brackets, do we still have a function or not. If so, this is deemed our render function, and this will be the function that reagent will fall back on whenever any of its elements change, not going through the outer and setting the atom to zero again.
It is very easy , especially at the beginning, to put the (let [] ...) in the inner function, or to define the atom in the inner etc. But let's try and figure out why we have to do it this way. Remember that react elements are immutable, and the only way to change them is by recalling their render function , the component, and supplying new arguments. If we were to define the atom inside the render function, how would you go about updating it? The only function that would have the scope of the inner function would be the inner function, which has it's value set once and for all. Each time it would be called the atom would be reset every time it was clicked, and so you wouldn't see anything... But what about supplying the atom as an argument for a form-1 component?
(defn like-job-post
"when we click the heart icon it should increment the like count atom, and as it dereferences,
we see how popular the job is getting. But as it is , this is all local state . And the only
people liking it is us..."
[likes]
[:div.likes
[:h2 @likes (if (= 1 @likes) [:h4 " person likes this..."] [:h4 " people like this..."])]
[:span
[icon "like"
:id (str "job-card__like-button_job-" 3)
:class "job__icon like job__icon__private job__icon--pointer"
;; here is where we start to see the headlights of the car we'll be crashing into...
;; as we're updating an argument, which would always be passed to us as (r/atom 0),
;; then we would need to make sure that the component outside is us is doing the work
;; of taking our return value and then passing the updated argument to us
;; which defeats the point of local-state.
:on-click #(swap! likes inc)]]])
I don't want to make it sound like form-2 components are a workaround, there are the perfect solution. They keep the separation of concerns away from other components, and by defining a simple wrapper, which hands the scope of the atom to the component, so when we call swap!, it is outside the immutable realm of the elements and we can then see the elements themselves updated as the value gets incremented.
The next part of our job card is the company tagline, the concise description of the company and/or the job itself. The taglines will vary in length but we need to have some space for the apply buttons and things, so they'll have to have a fixed length , with the rest of the information in the job post. We'll give the entire tagline to our "cutoff" component, which will take a segment off , proportional to the device's dimensions , and return the segment in a div. One way of doing this is to create a canvas object, allowing us to specify a set of dimensions (rows and height). We will not mount the canvas, it is just a reference to allow us to picture the accurately the dimensions of the string itself, there is no need to fill the canvas and mount it as it is a lot easier and lighter to just use the text, with the knowledge that it fits the card.
The thing is, once we set up a segment and the component gets mounted, we are not done. This is because things may happen over the course of the component's lifetime that cause the segment to change, for example a company that owns the post may wish to edit the tagline and therefore we would need a new segment.
In addition to this, it would mean the parent sizes of the outer card would have changed, and we need to see the properties of the parent to place the tagline nicely, meaning we can't get away with defining an independent render function, we need to have access to the parent and some stage and this is where r/create-class comes in.
In the event that a :component-did-update we would need to recall our render function , retake the dimensions and size the tagline appropriately. This is one of the lifecycle methods that all components, that extend React.Component, have access to. The key I'm referring to is one of the lifecycle methods, which we can define in form-3 components. This takes a map of the lifecycle method we want to implement and the function being the implementation. We can define the ellipsis class in this way by doing:
;; if you want to see the code for creating the canvas and sizing the text up,
;; visit : https://github.com/WorksHub/client/blob/master/client/src/wh/components/ellipsis/views.cljs
(defn ellipsis
"takes the entire tagline text, and the option to vertically center the tagline"
[text & [{:keys [vcenter?]}]]
(let [clearence 40 ;;px
id (name (gensym))
id-child (str id "-child")
measurer (atom nil)
parent #(.getElementById js/document id)
child #(.getElementById js/document id-child)
last-w (atom 0)]
(r/create-class
{:component-did-update
;; "this" will be the React.Component class itself
;; force-update will then takes this component and recall it.
(fn [this]
(when (not= @last-w (.-offsetWidth (parent)))
(r/force-update this)))
:component-did-mount
(fn [this]
(when (not= @last-w (.-offsetWidth (parent)))
(r/force-update this)))
:reagent-render
(fn [text]
(let [capped-text
(when (child)
(let [w (.-offsetWidth (parent))]
(reset! last-w w)
(cap-text text w (.-offsetHeight (parent)) measurer (child) clearence)))]
[:div.ellipsis-container
{:id id
:class (when vcenter? "ellipsis-container--vcenter")}
[:div.ellipsis-content
{:id id-child}
(or capped-text text)]]))})))
We make use of :component-did-mount so as to update the component, because when we render the child element is not setup yet, meaning capped-text on render is nil. Therefore, the full text is initially rendered, and once we've mounted the elements and their ids are established, we can update the component, call cap-text and we have our tagline properly formatted. In the case that the :component-did-update we just recall render, which re-mounts the component and resizes the tagline.
One interesting thing to notice is the use of :reagent-render over just :render. Fundamentally, when reagent functions are converted into classes, these react components take their properties in one big object, called the props , and they are accessed through this. As :render is a function pertaining to react, it means that the react component itself will expect this and nothing else. So if we had used :render instead, our function would only ever be called with one argument, it would work on the first invocation , no errors, as the arguments are in the scope of our component definition , in this case ellipsis. But when the function is recalled, the function gets separated. Moreover, if we supplied arguments to our form-3 functions which had multiple arguments, when specifying render it would omit the arguments on re-render and we wouldn't see changes occurring. This also applies for the local state that we setup before defining r/create-class. What we could do , which is not the prettiest of solutions , is to use (r/argv this) within our :render which would allows us to grab the parameters passed into :ellipsis if we had used :render. What :reagent-render allows us to do is , being outside of the native react api, it will do the work of maintaining our references and our scope to local data by calling things like r/argv for us. More on this quirk can be found on the reagent issues section here.
The last thing to do for our job card are the application buttons.
For the application section, we shouldn't allow a user to click the apply button if they have already applied, so that button should be disabled. Also, if they have applied , we should show them the state of their application, which could be in one of the following:
;; for a given keyword, we should return the appropriate string
#{:pending :approved} = "Pending"
#{:get_in_touch} = "Interviewing"
#{:pass :rejected} = "Rejected"
#{:hired} = "Hired"
So to convert a keyword, denoting a stage in the application , into the candidate's status we could do:
(defn state->candidate-status
[s]
(cond (s #{:pending :approved}) "Pending"
(s #{:get_in_touch}) "Interviewing"
(s #{:pass :rejected}) "Rejected"
(s #{:hired}) "Hired"))
So given the application state isn't false ,
(when state
[:div.state
[:span.applied-state "Status: " (state->candidate-status state)]])
The "More Info" button is fine to have regardless of who views the post, be it a candidate , an admin or the company who owns that post. But the company that owns it will probably not want to apply, but rather edit it, so in the case that it's them, we'll want to show that type of user a different button.
(defn job-card-buttons
"out of the job data, the id , state , slug and published are pulled.
the slug is the url fragment used in the wh frontend routing system,
as the unique identifier. Published is to check that the job is available for view,
and on the market"
[{:keys [id state slug published] :as job}
{:keys [user-has-applied? user-is-owner? user-is-company? applied? logged-in?] :as user}]
[:div.apply
(when state
[:div.state
[:span.applied-state "Status: " (state->candidate-status state)]])
[:div.buttons
[:a.button.button--inverted {:href (routes/path :job :params {:slug slug})}
(if user-is-owner? "View" "More Info")]
;; determine the type of user, and show the ability to edit or the ability to apply.
[user-button job user]]])
job-card takes a separate map for specifying the user type : admin or candidate, if they're logged in etc. We can pass this on to user-button and make things a lot easier. Doing this reduces the computations that the user-button component has to do, not calling other functions for their state etc, it will simply check the type of user and render either the button to edit if it is a company or an admin, or if the person is a candidate who has applied, show the disabled apply button, or if neither comes back as true then just show the option to apply for candidates who haven't or who aren't even logged in.
(defn user-button
"depending on if the user is viewing the post as a candidate,
or the user is in fact the admin, then the post will come with
functionality to edit the post, or if it is a candidate viewing
the card then there will only be the options of more-info and applying."
[{:keys [applied id is-company? is-admin?] :as job}]
(let [apply-id (str "job-card__apply-button_job-" id)
button-opts (merge {:id apply-id}
(when (or applied?
(and user-is-company?
(not user-is-owner?)))
{:disabled true}))]
(if (not user-is-owner?)
(when published
(let [job-page-path [:job :params {:slug slug} :query-params {:apply true}]]
[:a (if logged-in?
{:href (apply routes/path job-page-path)}
;; show-auth-popup is needed here to wrap our event dispatch for applying,
;; as the person may not be logged in at the time they click apply.
(interop/on-click-fn
(interop/show-auth-popup :jobcard-apply job-page-path)))
[:button.button button-opts
(cond applied?
"Applied"
user-has-applied?
"1-Click Apply"
:else
"Easy Apply")]]))
[:a {:href (routes/path :edit-job :params {:id id})}
[:button.button "Edit"]])))
We're just about to move onto re-frame now, and see how it ties into all our components, but first let's take a look at the entirety of the job file , with everything included, so you can see how it should all look together. It's not a problem if you don't understand certain re-frame conventions for the moment as we're just about to explore them!
Understanding re-frame
Much as what reagent does for elements, re-frame does for events. Decomposition is heavily endorsed, and the philosophy is to make each event in an event chain , much like each child component within a parent , as dumb as possible. They should be simple, taking their data in the parameters and any impure functions pushed to the outskirts of the rest of the app. Re-frame comes with an event queue, so when events are triggered, they get dispatched and placed on the queue where they wait. The functions themselves are waiting to be evaluated, the event's name is added, and re-frame has a registry on the side which records all event names , which are keywords.
In re-frame you'll see impure events all the time, and they are what make an application actually meaningful, so we need to make sure they do their job right. Data is a big part of an application, and where it's stored, how much global data is in different places, and how events gather data are all important questions. To tackle this problem re-frame comes with a reagent atom called app-db which we can make changes to , and it acts as an in-memory database for keeping track of things like sessions , form submissions etc. As re-frame controls the central source of data, it can plug it into events when they are being processed, making their job of finding the db themselves disappear. Events will take this database, but the events themselves will simply describe the shape they want the db to look, changes are done by what's called an effect, which is a type of event handler, but one specifically for making changes to the system.
That's probably too much talking so let's start from the very bottom and see what app-db looks like:
;; looking in re_frame/db.cljc
(def app-db (ratom {}))
;; now you can rewrite the atom to have a vector , or any other data structure, but as we'll see
;; re-frame has lended some it's functionality to assuming app-db will be a map, so if you do change
;; the structure you'll have to rewrite some logic...
Now we'll never want to modify app-db through events, as that would make them impure , harder to test and harder to integrate it with other events. We'll use effects to swap! data, and we need all events we define to be registered with re-frame, so it can reference it at the point of processing, and in the case of an effect handler , here is how we do it:
;; this effect is already written in re_frame/fx.cljc
;; :db
;;
;; reset! app-db with a new value. `value` is expected to be a map.
;;
;; usage:
;; {:db {:key1 value1 key2 value2}}
;;
;;
;; added an effect to the re-frame registry, which at it's core is a map of k/v
;; it differentiates by the kind of event, from the most pure (events which simply dispatch),
;; to the most impure (effects).
;; don't worry about the below map if you aren't familiar with re-frame , it acts as an example registry.
;; {:fx {:db #'handler-fn} :event {:event-name #'event-handler-fn}
;; :cofx {:coeffect-name #'co-effect-handler-fn} :sub {:sub-name #'sub-handler-fn}}
;; registering an effect , fx, and so it will be added to the :fx key.
(reg-fx
:db
(fn [value]
(if-not (identical? @app-db value)
(reset! app-db value))))
Now we need an event handler which will define a particular use for this effect. How about we convert the like-job-post component from a local-state component to a useful, global one. But still perfectly safe. Let's define the event that we want users to trigger , instead of #(swap! inc likes):
;; as we're defining an event, use reg-event-fx
(reg-event-fx
;; keep names unique , for the app and the registry's sake
::job/like-job-post
;; the first argument is the current map of everything, INCLUDING APP-DB
;; which we talked about re-frame being able to inject in for us, keeping the handler pure.
;; adding to the db isn't the only impure operation we may want to do,
;; but it is the only data repository we should be having, with cofx
;; being the map of all things impure. It may look like this :
;; {:db {:key1 val1 :key2 val2 :etc :etc} :another-effect #'(fn do-impure [args] ...)}
;; the other arg is the arg which we will pass to this event when we call it.
;; all we need to pass when calling ::job/like-job-post as re-frame handles app-db.
;; the first element is the event name itself, as we have to provide the name for the registry's sake
;; and the second element is any additional data that an event may need
(fn [cofx [_ _]]
;; each event should return a coeffects map. The keys specify however many effects need to be ran,
;; with the value being the data passed to the registered cofx. Co-effects differ from effects, as they use
;; impure functions to pump resources back into the coeffects map,
and setup resources for other handlers to use; whereas effects can use impurities for any old thing.
{:db (update-in (:db cofx) [:likes] inc)}))
For the sake of completeness , here is the cofx predefined in re-frame for updating our :db coeffect and pumping it back into the coffects map, allowing all handlers an up to have an up to date reference.
(reg-cofx
:db
(fn db-coeffects-handler
[coeffects]
(assoc coeffects :db @app-db)))
But the next question is how do we call these events? How do we push them onto the queue? Well, all we need to do is call the re-frame.core/dispatch function which does the work for us. Just supply a vector of [:event-name args] and it pushes it onto the queue. The queue itself is a FIFO (First In First Out) data structure for events, with dispatch being called typically when a button is clicked or an input form value is changed for example. In re-frame our queue needs to have some events which must fire when an application loads, and these are the first events which must be setup, one being the re-frame in-memory db. For example, the first event that needs to be fired in the workshub frontend is :init, and that loads app-db with whatever defaults it needs etc. Below we have the code for dispatching a job when somebody clicks to apply:
;; the argument job is the job itself,
;; and the :jobcard-apply is just an argument to denote the context
;; of where a candidate is applying from.
#(dispatch [:apply/try-apply job :jobcard-apply])
;; this does the work of putting the first item on the event queue,
;; with many more events and configurations to come.
;; the try-apply shouldn't know how to redirect the user, how to access the db etc.
;; it should just do it's bit in sending the data it's given to the right
;; endpoint for job applications, leaving the rest to the next handler that gets called.
Now remember that re-frame has it's own defined database, so the handler above only needs to be given the arguments from it's context and nothing else at this stage. When re-frame gets round to processing the event, it will pass the current state of the db, which we should've initialised at page load, and allow the handler itself to remain pure and work with that. But depending on the event itself, it may not want to specify just the db effect, it may also want to specify some of the effects native to the application, and in the workshub case, :graphql, show-auth-popup etc. In the event below we specify :show-auth-popup as we want to prompt the candidate to login if they want to apply, and then redirect to the post itself once that is done.
;; defining the :apply/try-apply event handler
;; first we need to register an event, and there are many different types,
;; and the type is specified by the suffix, in this case fx.
;; fx denotes effects , which means we want to change the re-frame db in some way.
;; we want to register an event handler that causes an effect, effects themselves
;; are impure and are handled by another handler, in this case , graphql, which takes
;; the query, the variables, and the handler for on-success and on-failure.
(reg-event-fx
:apply/try-apply
;; :apply/try-apply is the key, and this will be the value in the registry
;; re-frame supplies every handler with the map effects map it has , and we destructure for db
(fn [{db :db} [job event-type]]
;; check that this person is logged in, which is a flag set on log in
(if (db/logged-in? db)
;; this describes the next handler in the chain, we're going to dispatch
;; the :start-apply-for-job handler loads :logged-in , which itself will
;; execute the handler in the event that a person is logged in.
;; the map below is the effects map, the effects that
;; *this handler should specify*. In this case redirect based on the slug (url fragment)
{:load-and-dispatch [:logged-in [:apply/start-apply-for-job job]]}
{:show-auth-popup {:context (name event-type)
:redirect [:job :params {:slug (:slug job)} :query-params {:apply "true"}]}})))
So now we know all about events, their chain and how their modelled. Now onto the topic of subscriptions. Since the app-db is a reagent atom, we can reference it in our components and allow re-render when it changes. Although we don't to watch the whole thing as that would mean we re-render for any change, related or not. Subscriptions are slices of the app-db , they are atoms that will change whenever the watched value changes, and dereferencing the subscription atom will return the value.
We can reformat components to behave atomically, and call upon slices of the db, instead of having the data passed as arguments, we could remodel predicates like user-is-owner? and have it watch the db directly instead.
;; check the type of user and see if it = owner
(defn owner-type? [type]
(= type "owner"))
;; all the different means of working with data in re-frame needs to be registered,
;; be it a subscription , an event or effect etc.
(reg-sub :wh.user/owner?
;; subscriptions don't get given a coeffects map as they are only watchers of the :db coeffect
(fn [db _ _]
;; a lot of the time, subscriptions are simply there to keep an eye on a portion of the db,
;; and the work we do in this function can be done without any other arguments
;; so when our components call (subscribe [::company?]) , in the same way as dispatch,
;; we don't need any additional data to return what our component needs.
(owner-type? (get-in db [::sub-db ::type]))
;; now the value of this sub acts as a *sub-node* of the main db branch. If this node changes
;; then we re-render whatever component(s) are subscribed to this node.
))
And if we were to plug it into our components, we would traditionally call (subscribe :wh.user/owner?) and then dereference the atom we get, but it is important to remember the "etiquette" when dereferencing atoms has to be the same as the rules for dereferencing reagent atoms in form-2 components, otherwise it won't work , for the same reasons with re-rendering. Moreover a technique we can use to avoid this pothole is to utilise a function used in many a re-frame application, sadly not in core , but defined within our project as:
;; takes a vector that would otherwise be given to re-frame.core/subscribe,
;; and will return the value (dereferencing the given atom) for use.
(def <sub (comp deref re-frame.core/subscribe))
Then we can call (<sub [:wh.user/owner?])
;; rewriting the user-button check function from earlier
(defn job-card--buttons
[...]
...
[:a.button.button--inverted {:href (routes/path :job :params {:slug slug})}
(if (<sub [::owner?])
"View"
"More Info")]))
Now, for the owner subscription, whilst it works perfectly fine, there is another way which we can decouple the paths the subscription has to take into a separate subscription. Now this is fine for short get-in's , but if you were to sift through four or five layers then it isn't really recommended doing the below as the inefficiency outweighs its elegance:
;; we can take out the path of ::user/sub-db as the location of the db may change, within the map and
;; the subscription itself shouldn't have to know where the data comes from, just the principle that it has it,
;; so we write a sub for the ::user/sub-db slice
(reg-sub
::user
(fn [db _]
(get-in db [::user/sub-db ::type])))
Now this path can become the path that our ::owner? subscription is given , instead of expecting db, and it can simply pull ::user/owner? from that. Much like re-frame inserts arguments into the sub before calling it, we do the same by inserting what's called a signal function, called as such because each path to a database is called a signal, and the nodes created by subscriptions are called nodes of the signal graph (starting with app-db). The function we've been defining so far in our subs has been the computation function which does the job of taking a signal , which is typically just db, and transforming the data in some way, although computation is rather an over-statement as we rarely do complex transformations in a subscription itself, that would be delegated to another function.
(reg-sub
::owner?
(fn [_ _]
;; both the query-vector and dynamic-vector arguments are omitted, we just
;; want to reform the path that we give the subscription that's all.
;; this path will now be the first arg in the computation function
[(subscribe ::user)])
(fn [user]
(owner-type? user)))
All the parts of a subscription are essentially geared towards this computation function, we want to make sure it has all the data it needs, fed through arguments and the signal function return value is pushed in as the first arg. What's interesting to note is that the signal function args, if we were to supply them, would be pushed in as the second and third arguments to the computation function. We saw earlier how the query vector was used, as a way to provide the subscription with unchanging, additional values that are used to compare or whatever, whilst dynamic vectors are values which are additional , but can change and this means we might , supply our subscription with atoms or reactions, though the re-frame docs state this argument is near deprecated as even query-v sees very little use.
In the cases where we are using neither arguments, which is about 90% of the time, we can replace this unnecessary function with a little syntactic sugar, that simplifies things and allows us to just reference the sub itself:
;; is equivalent to the above
(reg-sub
::owner?
:<- [::user]
;; supply a vector of only 1 sub, is never a vector of more than 1 sub,
;; otherwise we would supply another of these.
(fn [user]
(owner-type? user)))
In the case it is only one, then we don't need to destructure as reg-sub will see this and just push the data without a vector wrapper; however if more than one marker is supplied then the first arg to the computation function is a vector of all the values.
;; example with random added data, all owners of a job post
(reg-sub
::all-different-admins
;; pull out company if a company owns the job
:<- [::company]
;; pull out admin , should always come back with data
:<- [::admin]
(fn [[company admin]]
[company admin]))
Now that we've got a fairly good understanding of subscriptions, we should think more about when and where is the best time to reach for them. In the cases of simple components, and by simple I always mean those which have state solely in their parameters, it doesn't make sense for it to be remodelled atomically if they wouldn't manage the state themselves; but the opposite case is true for components that should have subscriptions and not rely on parameters, as the parent would do the management and be re-rendered with the child.
There are always exceptions to the rule though, and turning to our job-card specifically there is one other aspect to think about. Whilst job-card does contain subscriptions, it is used in quite a few different parts of the website, and it would be nice if such an important component was simple, pure and easily reusable. There are many different types of jobs that job-card will need to show, from jobs of a certain company, certain language etc. So we'd have to take the penalty of re-rendering the parent, although it isn't really felt if the parent is simply a wrapper, take the company-jobs parent component in issue/views.cljc for example:
(defn company-jobs
[logged-in?]
(let [jobs (<sub [::subs/company-jobs])
company-id (<sub [:user/company-id])
admin? (<sub [:user/admin?])
has-applied? (some? (<sub [:user/applied-jobs]))]
(when-not (and jobs (zero? (count jobs)))
[:section.issue__company-jobs
[:div.is-flex
[:h2 "Jobs with this company"]
[link "View all"
:company-jobs :slug (<sub [::subs/company-slug])
:class "a--underlined"]]
[:div.company-jobs__list.company-jobs__list--twos
(if jobs
(doall
(for [job jobs]
^{:key (:id job)}
[job-card job {:liked? (contains? (<sub [:user/liked-jobs]) (:id job))
:user-has-applied? has-applied?
:logged-in? logged-in?
:user-is-owner? (or admin? (= company-id (:company-id job)))
:user-is-company? (not (nil? company-id))}]))
(doall
(for [i (range (<sub [::subs/num-related-jobs-to-show]))]
^{:key i}
[job-card {:id (str "skeleton-job-" (inc i)) :slug "#"} {:logged-in? false}])))]])))
Aside from the data about the job itself, which is a lot, job-card also requires additional data, to see if the user viewing each job is logged in, and if they're an owner, an admin or a candidate; It would do the component a lot of good if it didn't need to worry about fetching all the data itself and focused purely on the displaying.
The last thing we'll cover are the different ways we can store all our events, subscriptions and components. Traditionally, the standard procedure is to have it done like this:
components/
cards/
db.cljs
events.cljs
subs.cljs
views.cljs
But not every component needs their own app-db modifications, subscriptions or maybe even events. For simpler components it suffices to just do:
components/
job.cljs ;; for components that use subs, events and stuff from other components.
When we are able to "de-atomise" components, and have their data come in through parameters , we could use this structure. Though I find the standard template to be too much and the second too little. The middle is probably best, with the home for simpler components finding themselves in common/src/wh/components, and the more complex sitting in client/src/wh/components , although the reasoning behind putting things in client is because they need their own events etc. although only error and forms need this structure, so maybe we move some things around.
And that about wraps up our excursion of the job-card component. You can find the most up to date version of it here and if you want to try out my slightly altered version , more comments etc , and the like-job-post thing you can, just replace it for this job file before starting the dev server.

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!