The Science Behind Functional Programming
Rafa Paradela
10 Apr 2018
•
16 min read

Over the course of three months, I was fortunate enough to attend three awesome conferences: Lambda World in October, ScalaIO in November, and Scala eXchange in December. I found that after attending almost 20 talks and several workshops, there are several subjects worthy of discussion. However, I want to share with you the main two conclusions I came to after looking back on my experiences.
More and more developers are interested in Functional Programming
Speaking objectively, there are a bunch of facts that show this trend. For example, the proliferation of a new functional language (or languages that encourage functional techniques). I’ve been playing around with Google Trends, and it says that searches for “higher order functions” have increased over 250% in four years, “js functional programming” over 750%, and “java functional programming” over 1,050%.
I’m also basing this statement on my perception, because, lately, I’m seeing more and more developers show interest in techniques and patterns that used to be exclusive of functional programming. And another shocking fact from my point of view is that a small city with a population of only 100,000 in Southern Spain hosts an international conference on Functional Programming. If Lambda World has doubled the number of attendees in two years, this can only mean one thing: people want to learn about FP.
People want to understand the science behind Functional Programming
Here’s an interesting tidbit for you: there were more than a hundred speakers at these events, but only two of them presented at all three, Bartosz Milewski and Daniela Sfregola spoke in Cádiz, Lyon, and London. And yes, they both talked about Category Theory.
People love Milewski keynotes, and organizers know that. They also love learning Category Theory with speaker’s like Phillip Walder doing a closing keynote, or with Eugenia Cheng opening. All these mathematicians have shown a brand of skepticism, often stating, “Wow, look how many people are now interested in this science which I’ve been studying for decades!!”. I hope these arguments are sufficient to demonstrate this idea. I think it’s clear that developers have become increasingly aware of one reality, one that Daniela expressed wonderfully: “After learning a little bit of Category Theory, I could understand why we do things the way we do, I was able to improve my code by choosing the right pattern for the problem I was trying to solve”.
This is what I want to talk about in this article. I will give a brief overview of the categories that are behind some computation patterns. Unlike most of the articles on Category Theory, I’m not going to be using Haskell to show code examples, nor Scala, in spite of learning all these concepts with the language. Instead, I’m very excited to be able to use Kotlin in this post, leveraging some of the cool features provided by Arrow.
What is Category Theory?
One of my favorite definitions comes from Dr. Eugenia Cheng who says that Category Theory is the mathematics of mathematics. She also expands this concept defining mathematics as the logical study of how logical things work. Overall, this description provides an idea of Category Theory is, in a global sense.
However, Sfregola’s definition, Category Theory is about how things compose, and Milewski’s, Category Theory is the science of composition and abstraction fit better with the approach of this article.
Why is knowing Category Theory relevant to programming?
If you’re a developer, you probably spend the majority of your working-day (or maybe more) mainly doing two things, even if unconsciously - composing and abstracting.
-
Composition: Sofware developing is about decomposing once and again, source files, classes, functions, data structures, etc. and composing again to do bigger programs… Without the ability to compose/decompose, we would not be able to program. We need the science of composition.
-
Abstraction: As developers, it’s difficult to keep the details of implementations in our heads. However, what’s helpful, is to keep a short description in mind, of what the function is doing, or what a data type is for…no matter how they’ve been implemented. From one level to another, we continuously omit details in our minds, to the extent that we forget what is inside various functions, and solely keep signatures in mind for knowing how they compose each other.
My dear friends, there is no better science to explain composition and abstraction than Category Theory.
What is a category?
From a mathematical perspective, a category consists of a series of objects connected by arrows.
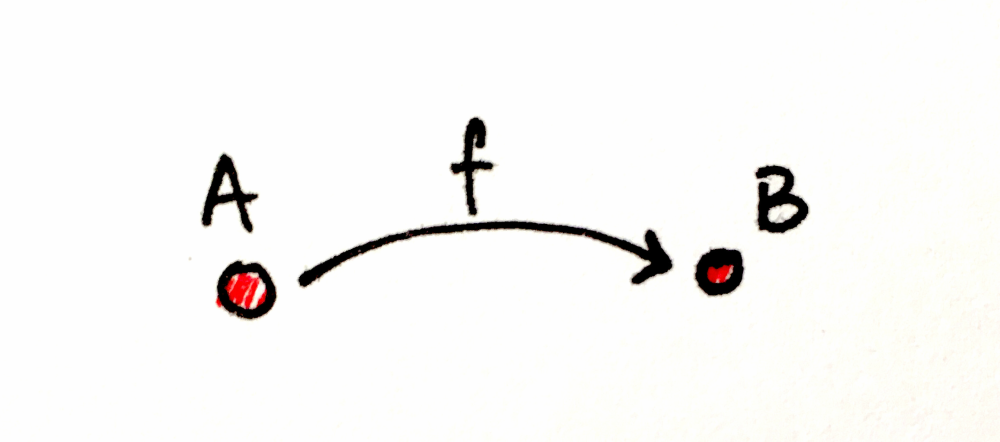
It doesn’t matter what the objects are; they can be whatever you can imagine, chairs, flowers, etc. What defines a category is how the arrows compose. In other words, the relationship between arrows (very often called morphisms as well).
Composition:
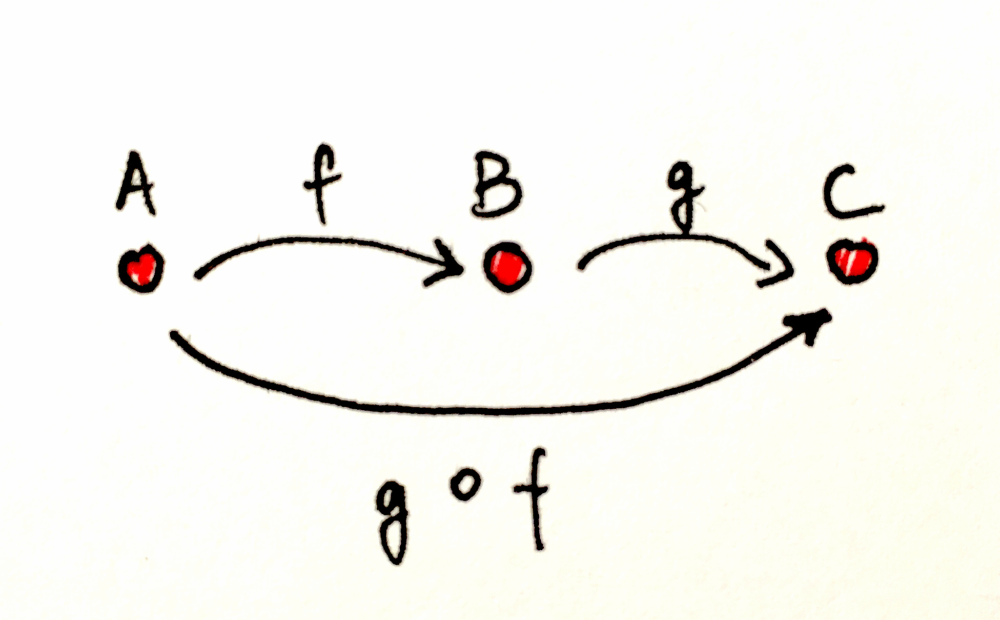
If we can go from A to B using the morphism f, and from B to C using g, it means that implicitly we have the composition of both arrows, called g ∘ f (g after f), to go from A to C.
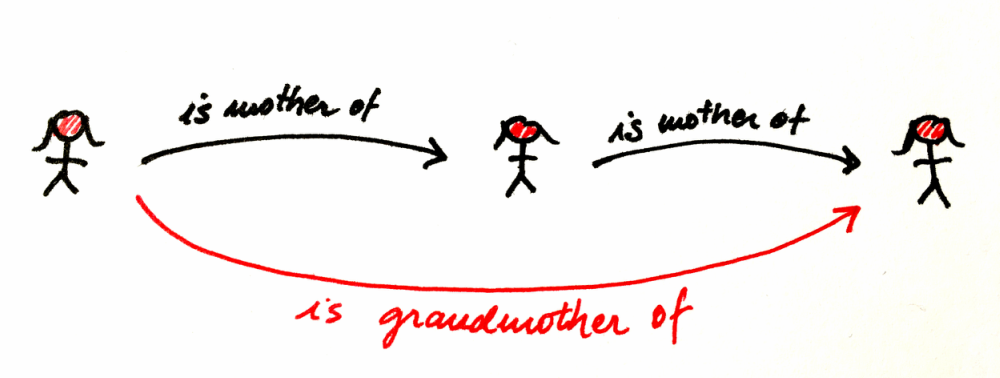
Somehow, we are continuously composing in our mind, to omit those relationships we can infer implicitly:
The composition of morphisms should satisfy a couple of laws to make the category valid:
Identity for composition: For every object A, there is an arrow which is a unit of composition. This arrow loops from the object to itself. Being a unit of composition means that, when composed with any arrow that either starts at A or ends at A, respectively, it gives back the same arrow. The unit arrow for object A is called idA (identity on A). The composition of identity ensures that the morphism f starts and ends in the same objects that f ∘ idA and idB ∘ f.
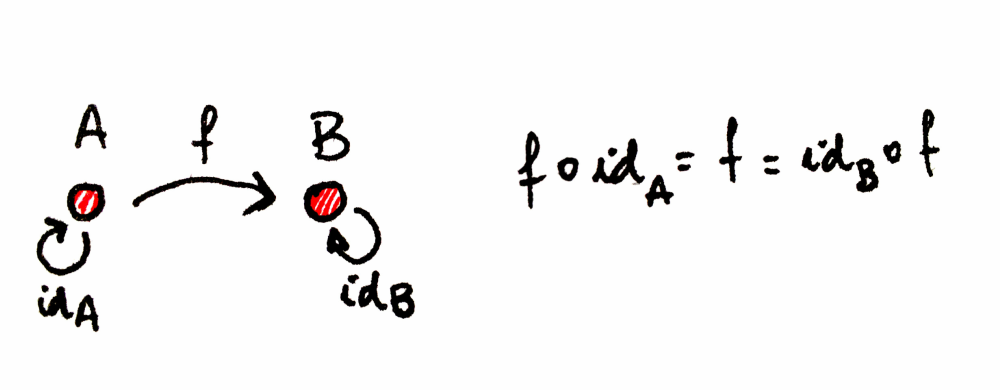
Associativity of Composition: If you have three morphisms, f, g, and h, that can be composed (that is, their objects match end-to-end), you don’t need parentheses to compose them. In math notation this is expressed as (h∘g)∘f = h∘(g∘f) = h∘g∘f.
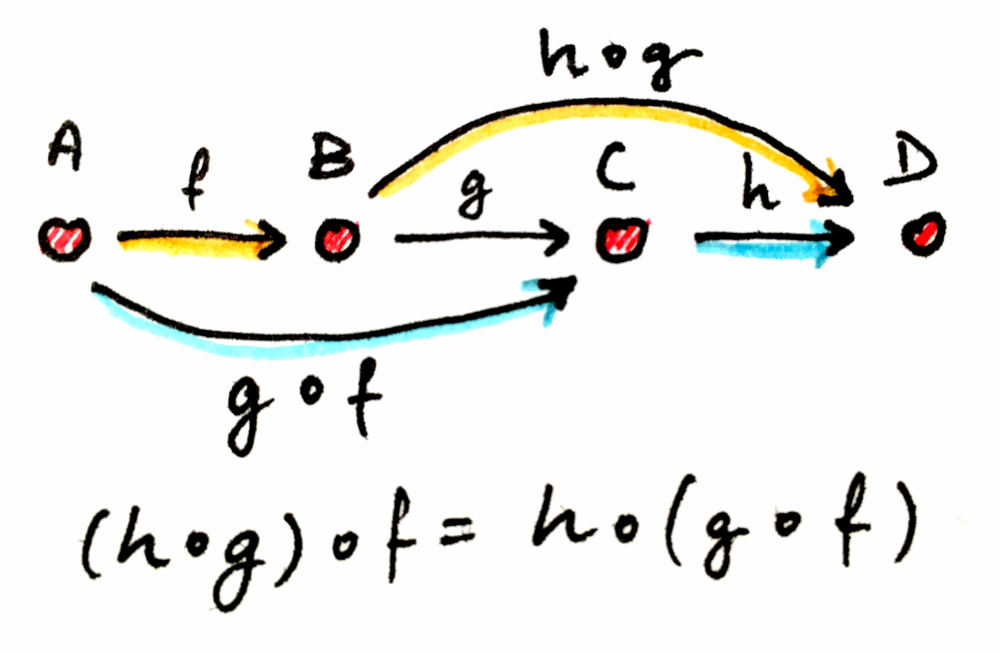
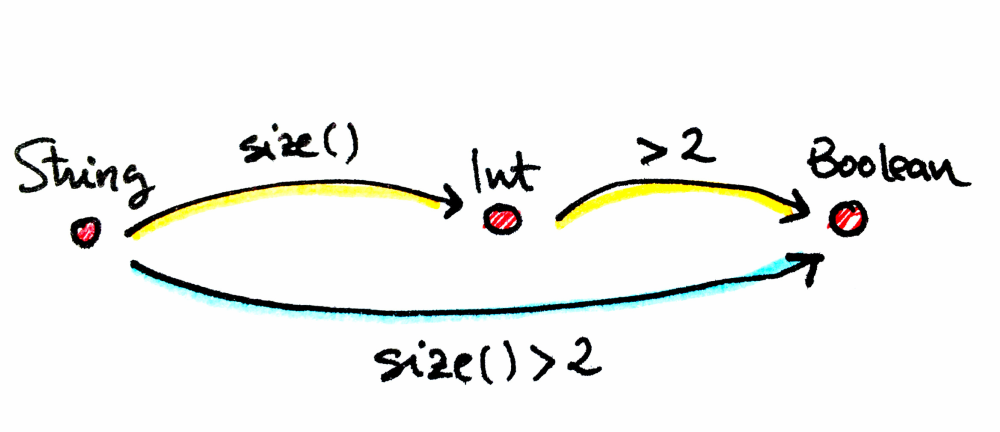
To help you to understand the associativity of the composition let’s see the same concept but in one concrete category, related to programming. Let’s consider a category where objects are types of data (Int, String, Boolean, etc.) and the morphisms are functions. In this particular category, can the function size() be a morphism between String and Int? Of course, it can. Being String the set of all the possible strings, and Int the set of natural numbers for instance.
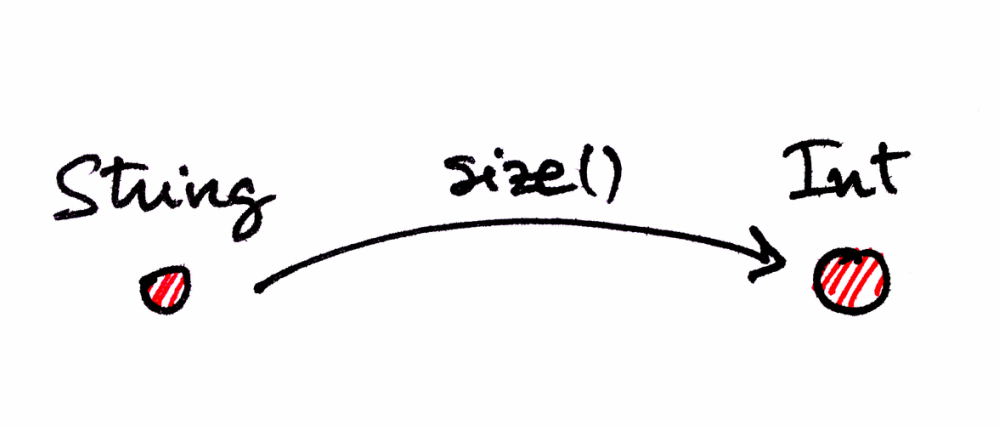
fun f(a: String): Int = a.length
So, this category is only valid if functions can be composed, accomplishing the composition laws, for all the members of the sets. You are developers, and you are familiar with functions composition, aren’t you?
In Kotlin:
fun f(a: String): Int = a.length
fun g(b: Int): Boolean = b > 2
fun gAfterf(a: String): Boolean = g(f(a))
Let’s see some famous categories
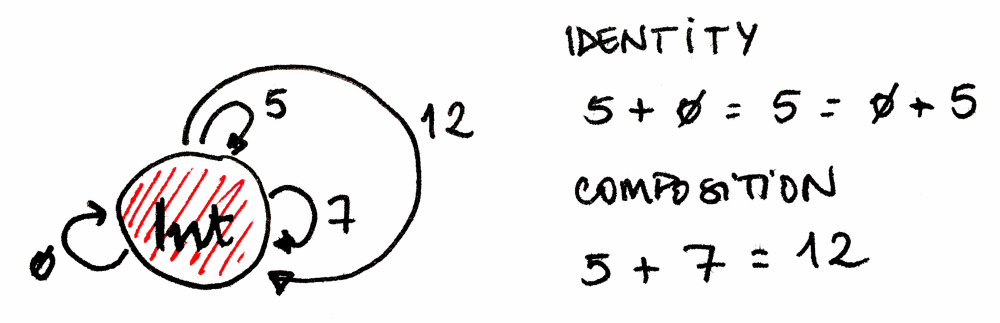
Monoid Mathematically speaking, monoid is the concept behind basic arithmetics. Every monoid can be described as a single object category with a set of morphisms that follow appropriate rules of composition.
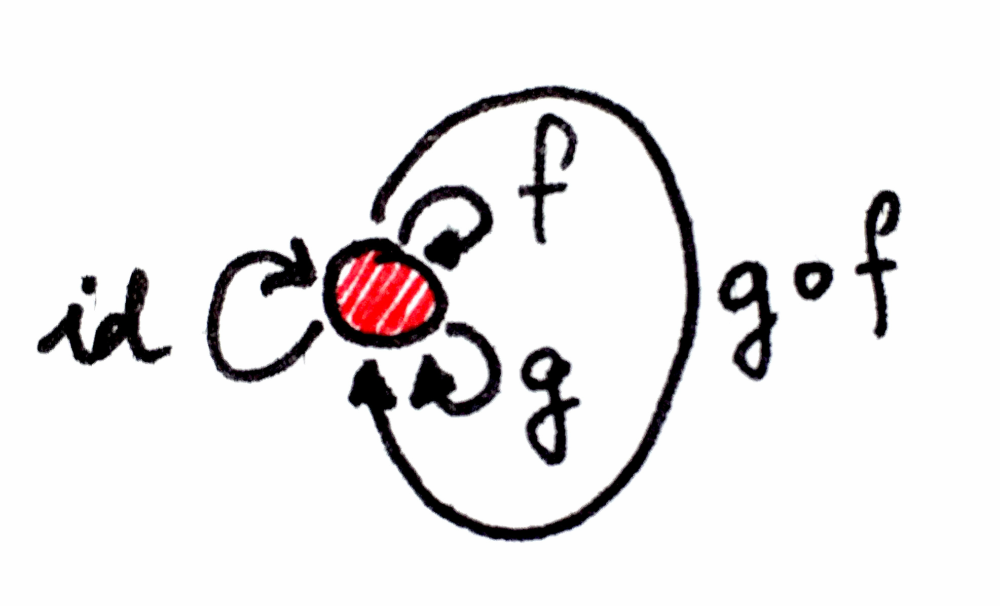
Traditionally, a monoid is defined as a set with a binary operation. All that’s required for this operation is that it’s associative and that there is one special element that behaves like a unit with respectively.
Monoids are ubiquitous in programming. They show up as strings, lists, foldable data structures, futures in concurrent programming, events in functional reactive programming, and so on. For instance, try to imagine the object that represents every natural number and one function f which is the operation of adding 5. It maps 0 to 5, 1 to 6, 2 to 7, and so on. Now imagine another function g which adds 7. In general, for any number n there is a function of adding n — the “adder” of n. How do adders compose? The composition of the function that adds 5 with the function that adds 7 is a function that adds 12. So the composition of adders can be made equivalent to the rules of addition. That’s good too: we can replace addition with function composition. There is also the adder for the neutral element, zero. Adding zero doesn’t move things around, so it’s the identity function in the set of natural numbers.
For that reason, Monoids are usually used to collapse data. How can we represent this composability behavior in programming? Well, if we continue with the analogy of treat objects as types, we can use type classes to express a behavior associated with a type. Although Kotlin does not provide them natively, with Arrow, we can build our own type classes. This could be the one to express composability: Monoid.
@typeclass
interface Monoid<A> : TC {
fun empty(): A
fun combine(a: A, b: A): A
}
Once Monoid is defined as a type class, we are able to create instances of Monoid for every type that can be combined, for example, strings, lists, and colors. Colors? Let’s try.
data class Color(val red: Int = 0, val green: Int = 0, val blue: Int = 0)
Once again, thanks to Arrow, we can easily instantiate our typeclasses.
Arrow provides several ways to define [instances](http://arrow-kt.io/docs/patterns/glossary# instances) for type classes. Using @instance, we can implement what empty and combine mean for Color.
@instance(Color::class)
interface ColorMonoidInstance: Monoid<Color> {
override fun empty(): Color = Color()
override fun combine(a: Color, b: Color): Color = Color(
red = min(a.red + b.red, 255),
green = min(a.green + b.green, 255),
blue = min(a.blue + b.blue, 255))
}
An instance is an interpretation of how to compute operations to fulfill a defined behavior. In this case, for example, I have interpreted that the neutral element (the neutral color) is black rgb(0, 0, 0), and the combination of colors is the addition of each channel, up to 255.
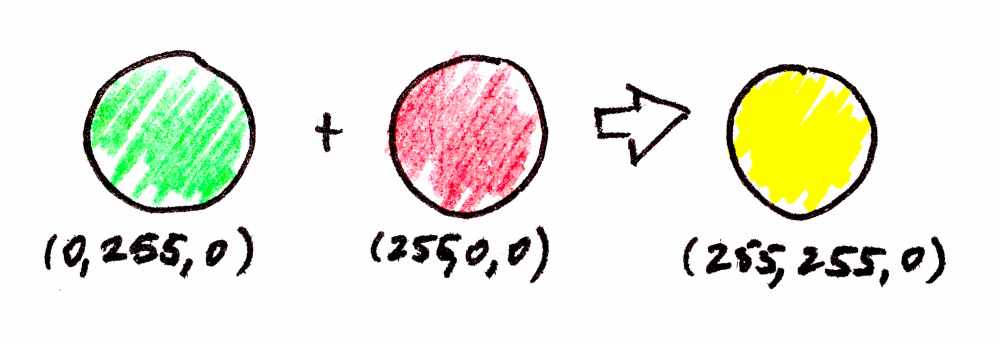
This is just my interpretation, and it’s as valid as any other, as long as it accomplishes monoidal laws, which are being written down as unit tests in Arrow.
What if we also add some syntaxes to let Monoid instances combine with postfix notation?
inline fun <reified A> A.combine(b: A, FT: Monoid<A> = monoid()): A = FT.combine(this, b)
With some “magic”, an implicit instance of monoid() is injected in the context, and we can combine colors like this:
val green = Color(green = 255)
val red = Color(red = 255)
val yellow = green.combine(red) //Color(255, 255, 0)
Functor
Let’s assume we have an imaginary category (a wonderful category indeed) where we know how to convert a pyramid into a cylinder. Can you imagine? Let’s call it category C, and it’s 100% valid, as far as it fulfills composition laws: identity and associativity.
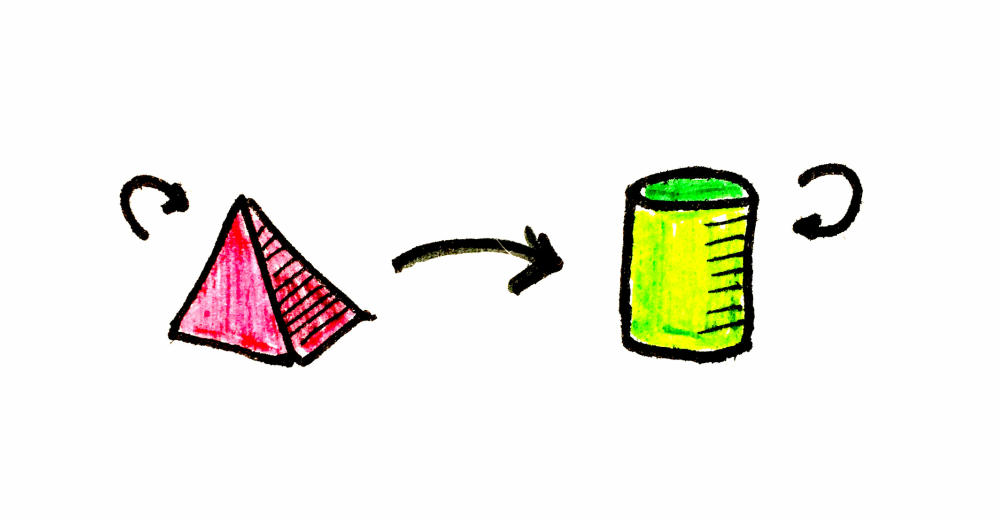
Now we are assuming that there is another similar category, where we know how to convert a box containing a pyramid into a box containing a cylinder. This category is called D. Basically, they are the same pyramid and the same cylinder, but in a different context.
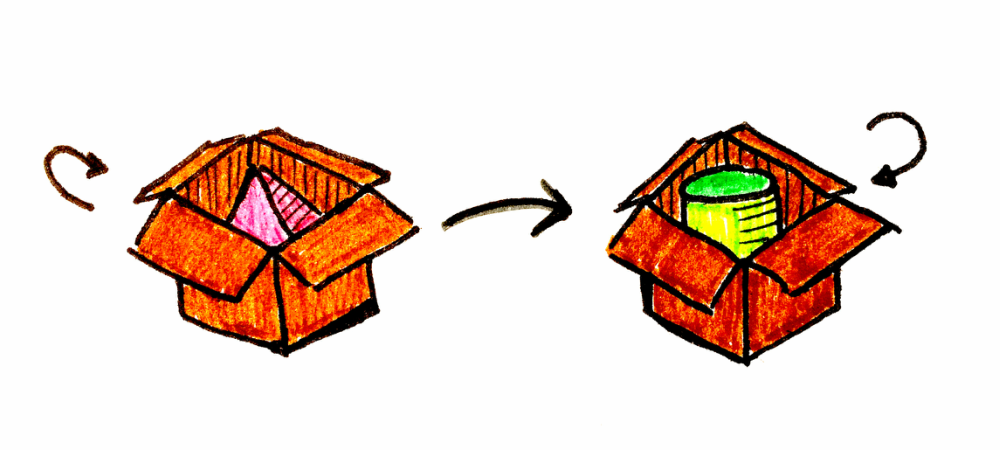
A functor is a mapping between categories. Given two categories, C and D, a functor F maps objects in C to objects in D — it’s a function of objects.
In a general sense, if a is an object in C, we’ll write its image in D as Fa. But a category is not just objects; it’s objects and morphisms that connect them. A functor also maps morphisms; it’s a function of morphisms.
In our example, a is the pyramid, b is the cylinder, and F is the box.
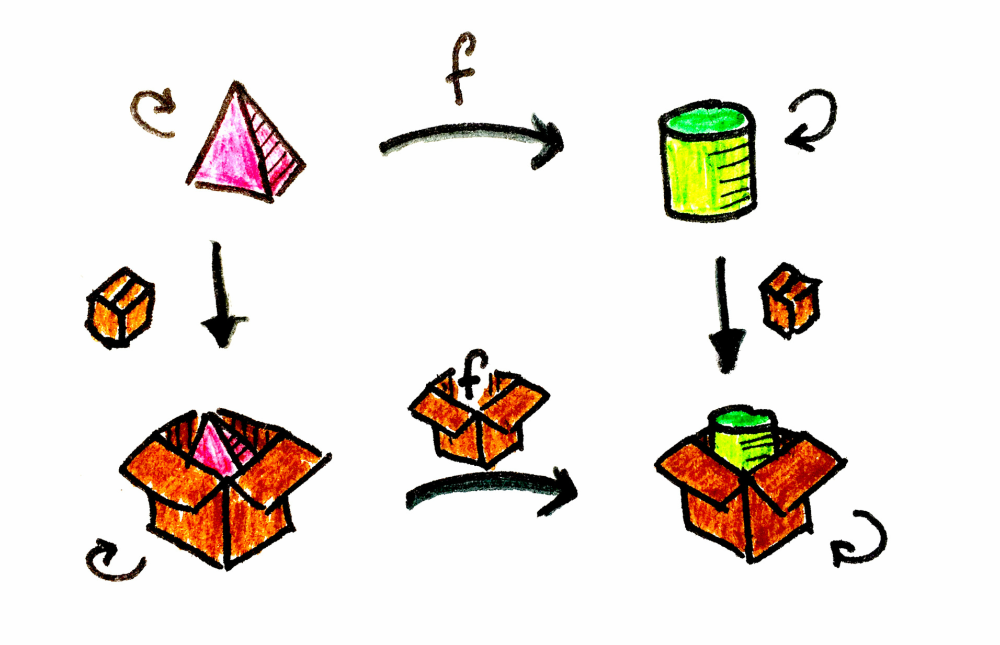
Let’s get down to earth and talk about programming. We have our category of types and functions, and F would have a context, represented by a type constructor (since it maps from one type to the other). We often find ourselves in situations where we need to transform the contents of a data type. And mapping the function of the functor allows us to safely compute over values under the assumption that they’ll be there returning the transformation encapsulated in the same context.
Arrow gives us several higher-kinds that can behave as a functor, for instance, Option, NonEmptyList, and Try. Why don’t we create another data type and its instance for functor? Building a type constructor is very simple:
@higherkind
sealed class Box<out A> : BoxOf<A>
object Empty : Box<Nothing>()
data class Full<out T>(val t: T) : Box<T>()
As you probably notice, Box<T> is a simplified copy of Option from Scala or Maybe from Haskell. It’s just an ADT (Algebraic Data Type), that like any other coproduct, can only be one value: Empty or Full<T>. We can add anything into the Box context: the number 1, the word “hi”, or even the color blue.
val box1: Box<Int> = Full(1)
val boxHi: Box<String> = Full("Hi")
val boxBlue: Box<Color> = Full(Color(0, 0, 255))
We are going to code down the functor behaviour in the same way as we did above, by creating a new type class. And when I say functor behaviour, I mean its ability to map over the computational context of a type constructor.
@typeclass
interface Functor<F> : TC {
fun <A, B> map(fa: Kind<F, A>, f: (A) -> B): Kind<F, B>
}
In other words, given a packaged pyramid (Kind<F, A>) and a function to convert pyramides into cylinders ((A) -> B), it returns a packaged cylinder (Kind<F, B>).
Note: In Arrow, Kind is an interface to represent generic higher-kinds. Now, when you see Kind<F, A> you should assimilate it as A lifted to the context F. Kind<Box, Color> is Box
If we create an instance of Functor for our box, we can map its content. Another great feature provided by Arrow is the capability for deriving instances, with @deriving(Functor::class). But, we need to implement map:
@higherkind
@deriving(Functor::class)
sealed class Box<out A> : BoxOf<A> {
fun <B> map(f: (A) -> B): Box<B> = when (this) {
Empty -> Empty
is Full -> Full(f(this.t))
}
companion object
}
object Empty : Box<Nothing>()
data class Full<out T>(val t: T) : Box<T>()
The implementation of map here is very trivial, if the box is empty we return the empty box, if it contains something, we apply the function to the content, and the result is returned within a box (Full(f(this.t))). Of course, any instance of functor should fulfil its laws.
Good! Now we can, for instance, transform a box of colour into a box of integer.
val boxInt: Box<Int> = Full(Color(0, 0, 255)).map{ it.blue } //Full(255)
Applicative
To recapitulate, we started off by talking about one category with only one object, then we talked how the functor can map elements between two categories, and now let’s jump to another abstraction level.
Applicative is another structure built on top of Functor, where arrows link objects as usual but with one special particularity: objects can be morphisms as well. BOOM!
We said that objects could be whatever we want, why not a morphism? Maybe it’s easier if we move again to programming analogy, where objects are types and morphisms are functions. Functions are another type, aren’t they? That is to say, in this category, there can be one object which is the set of all the functions that get A and return B.
If in category C, the arrow that converts a pyramid into a cylinder was called f, in this new category, we are lifting this arrow f in the context F as well (remember that F is the context, the box in our example).

Continuing with the analogy, if Functor has the combinator map, which is a phenomenal ability because lets us get a result (B) lifted to a context, just having an incoming packaged object (A) and the operation to convert A into B. Now the Applicative category, taking into account the particularity exposed above, it has other abilities:
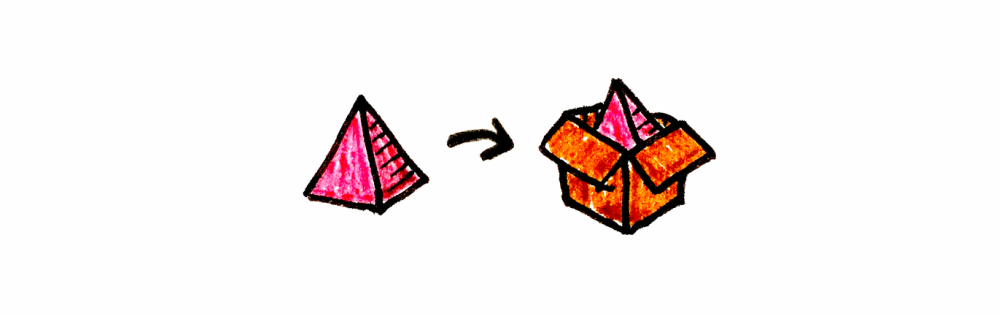
pure:Is the ability to lift an object to a context, that is to say, putting something inside a box, that is to say,(A): Kind<F, A>.
ap:Apply a function inside the type constructor’s context. It’s easier if you see the signature(Kind<F, A>, Kind<F, (A) -> B>): Kind<F, B>. It’s like map, but as I said before, instead of requiringfit requiresF[f]
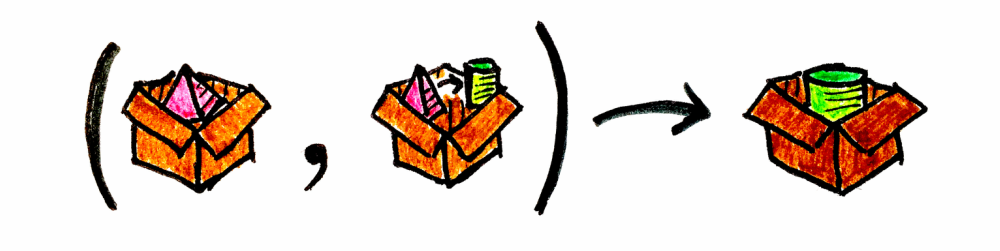
product:Given two packaged objects, it provides the packaged cartesian product of both:(Kind<F, A>, Kind<F, B>): Kind<F, Tuple2<A, B>>.
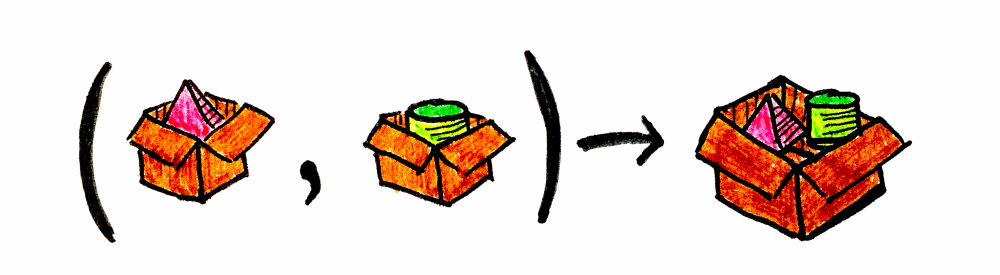
map2:Map two values inside the type constructor context and apply a function to their cartesian product: (Kind<F, A>, Kind<F, B>, (Tuple2<A, B>) -> Z): Kind<F, Z>
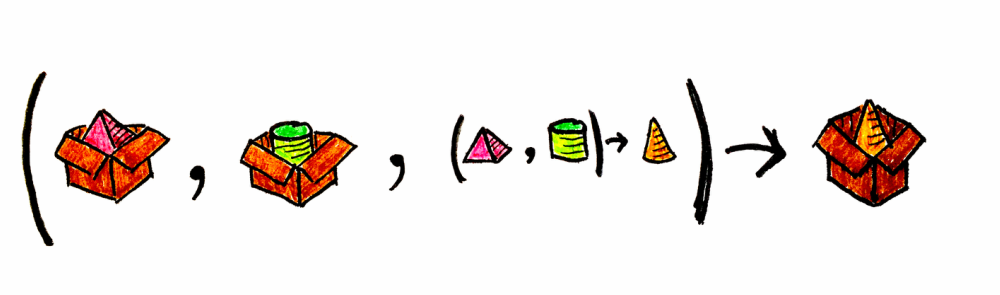
Once again, let’s count on the code to assimilate this concept.
@typeclass
interface Applicative<F> : Functor<F>, TC {
fun <A> pure(a: A): Kind<F, A>
fun <A, B> ap(fa: Kind<F, A>, ff: Kind<F, (A) -> B>): Kind<F, B>
override fun <A, B> map(fa: Kind<F, A>, f: (A) -> B): Kind<F, B> = ap(fa, pure(f))
fun <A, B> product(fa: Kind<F, A>, fb: Kind<F, B>): Kind<F, Tuple2<A, B>> = ap(fb, map(fa) { a: A -> { b: B -> Tuple2(a, b) } })
fun <A, B, Z> map2(fa: Kind<F, A>, fb: Kind<F, B>, f: (Tuple2<A, B>) -> Z): Kind<F, Z> = map(product(fa, fb), f)
}
Applicative implements Functor, so it needs to override map, which can be expressed in terms of ap and pure. If we want to have an instance of Applicative for our Box, we again have two choices: to build our own implementation or let Arrow derive the instances of all the type classes for the Box, according to all the functions implemented for Box. Let’s go with the second choice!
@higherkind
@deriving(Functor::class, Applicative::class)
sealed class Box<out A> : BoxOf<A> {
fun <B> map(f: (A) -> B): Box<B> = ???
fun <B> ap(ff: BoxOf<(A) -> B>): Box<B> = ???
fun <B> product(fb: BoxOf<B>): Box<Tuple2<A, B>> = ???
fun <B, Z> map2(fb: BoxOf<B>, f: (Tuple2<A, B>) -> Z): Box<Z> = ???
companion object {
fun <A> pure(a: A): Box<A> = Full(a)
}
}
In this example, the implementation is not that important, but if you are interested, you can take a look at it here.
We often find ourselves in situations where we need to compute multiple independent values resulting from operations that do not depend on each other. In the following example, we will define two invocations that may as well be remote or local services, each one of them returning different results in the same computational context of Box:
fun getPyramidFromDB(name: String): Box<Pyramid>
fun getCylinderFromWS(name: String): Box<Cylinder>
This more or less illustrates the common use case of performing several independent operations where we need to get all the results together:
val maybePyramid: Box<Pyramid> = getPyramidFromDB("MyPyramid")
val maybeCylinder: Box<Cylinder> = getCylinderFromWS("MyCylinder")
Box.applicative().map2(maybePyramid, maybeCylinder, { t -> Cone(t.b.name) }) //Box<Cone>
The point here is to use Applicative structure when the ingredients of the recipe don’t depend on one another. In this case, we don’t need anything related to pyramides to get a cylinder. Nor inversely.
Monad
Here comes the most embarrassing part of this post since I’m not a mathematician and this explanation is not very academic. However, it focuses on the pragmatic sense of the Monad, instead of the mathematical sense.
As we saw above, we already have some tools to deal with lifting results to a context. In fact, thanks to Applicative we can map several independent boxes into a result, by computing an operation with their contents.
The biggest advantage of Monads, is the ability to manage dependent nested operations without worrying about having one box inside another. Monads can flatten nested contexts, and this is a powerful capability. You will see the issue if we change to our previous example. Imagine that we need a pyramid in order to get a cylinder:
fun getPyramidFromDB(name: String): Box<Pyramid>
fun getCylinderFromWS(pyramid: Pyramid): Box<Cylinder>
As you can see, getPyramidFromDB gives us a pyramid, but it’s inside a context because it might not exist (Option), or will take a little bit longer (Future), or whatever. But getCylinderFromWS does not expect a pyramid with any effect, it requires just a pyramid. You might think, why don’t we use map, to manipulate the content? Let’s see:
val maybePyramid: Box<Pyramid> = getPyramidFromDB("MyPyramid")
maybePyramid.map { p -> getCylinderFromWS(p) } //Box<Box<Cylinder>>
Something is wrong. We need some extra tools to handle Box<Box<Cylinder>>. flatten to the rescue, whose signature is (Kind<F, Kind<F, A>>): Kind<F, A>).
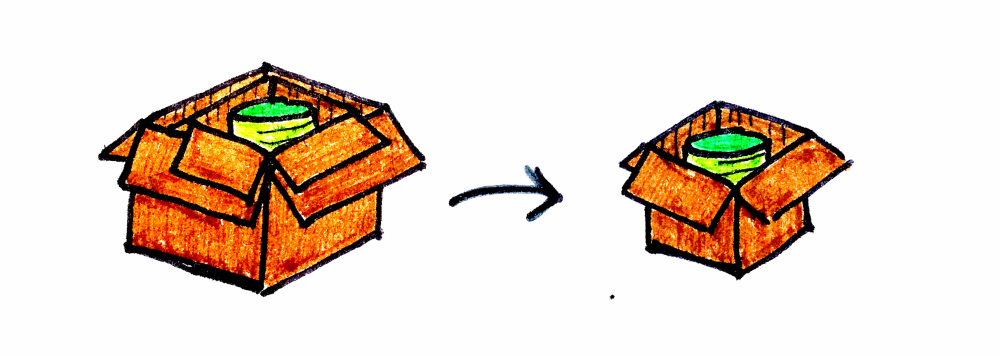
If we put map and flatten together, we can implement another combinator called flatmap whose signature is: (Kind<F, A>, f: (A) -> Kind<F, B>): Kind<F, B>.
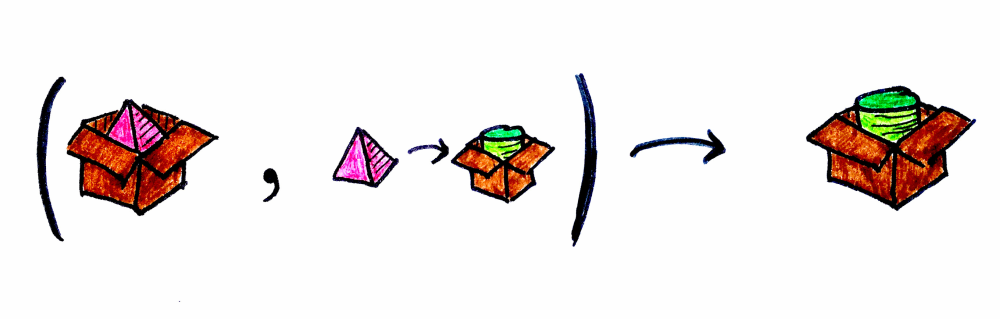
With this said, the type class which expresses these abilities could look like this:
@typeclass
interface Monad<F> : Applicative<F>, TC {
fun <A, B> flatMap(fa: Kind<F, A>, f: (A) -> Kind<F, B>): Kind<F, B>
fun <A> flatten(ffa: Kind<F, Kind<F, A>>): Kind<F, A> = flatMap(ffa, { it })
}
We are going to delegate the instance derivation of Monad for Box, to Arrow again. And then we’re able to chain the set of dependent operations in a monadic way:
val cone: Box<Cone> = getPyramidFromDB("MyPyramid").flatMap { pyramid ->
getCylinderFromWS(pyramid).map { cylinder ->
Cone(cylinder.name)
}
}
Monad comprehension I want to end by showing one last example that illustrates another cool feature provided by Arrow. So let’s imagine this scenario: We are building a program that, given a user id, can provide the user’s favorite artist in PDF format. To do so, we have these services:
object UserRepository {
fun getUser(id: String): Option<User>
}
object Spotify {
fun getFavouriteArtist(artist: String): Option<Artist>
}
object Wikipedia {
fun getArticle(title: String): Option<Page>
}
object Converter {
fun toPDF(page: Page): Option<PDF>
}
In light of the above, it seems like the computation we want to build fits a monadic structure, right? Since operations depend on each other and the result comes lifted to a context, Option, in this case, I would ask myself, is there an instance of Monad for Option? Actually, there is. Arrow did it. Therefore, we can do this:
val pdf: Option<PDF> = UserRepository.getUser("123").flatMap { user ->
Spotify.getFavouriteArtist(user.spotifyUsername).flatMap { artist ->
Wikipedia.getArticle(artist.name).flatMap { page ->
Converter.toPDF(page)
}
}
}
This would give us exactly what we want. Other languages, however, provide syntactic sugar to express this monadic structure, whose purpose is to compose sequential chains of actions in a style that feels natural for programmers of all backgrounds. Kotlin doesn’t have this feature yet, but as I said previously, Arrow offers this super cool idiom: Monad Comprehensions
Now, we can write down the same set of operations like this:
val pdf: OptionOf<PDF> = Option.monad().binding {
val user = UserRepository.getUser("123").bind()
val artist = Spotify.getFavouriteArtist(user.spotifyUsername).bind()
val page = Wikipedia.getArticle(artist.name).bind()
Converter.toPDF(page).bind()
}
You can find all the code used in this post in this repo. That, in my opinion, is a good place to start if you want to play with Arrow.

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!